言語処理100本ノック 2020 第3章
Created: 2020-04-29
言語処理100本ノック 2020 - NLP100 2020
関連記事: tag 言語処理100本ノック
code
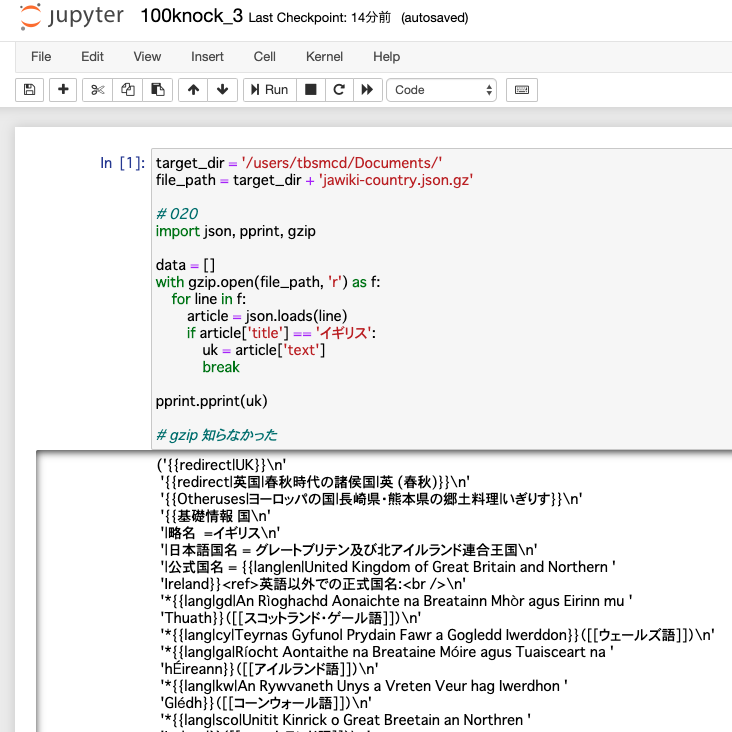
target_dir = '/users/tbsmcd/Documents/'
file_path = target_dir + 'jawiki-country.json.gz'
# 020
import json, pprint, gzip
data = []
with gzip.open(file_path, 'r') as f:
for line in f:
article = json.loads(line)
if article['title'] == 'イギリス':
uk = article['text']
break
pprint.pprint(uk)
gzip モジュールは知らなかった。
#021
import re
pattern = re.compile(r'(\[\[Category:.*\]\])', re.MULTILINE)
res = pattern.findall(uk)
for line in res:
print(line)
re.MULTILINE(re.M) などのオプションを忘れている。
#022
import re
pattern = re.compile(r'\[\[Category:(.*)\]\]', re.MULTILINE)
res = pattern.findall(uk)
for line in res:
print(line)
シンプル
# 023
# セクション?
# ref. https://ja.wikipedia.org/wiki/Help:%E3%82%BB%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3#%E3%82%BB%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3%E3%81%AE%E4%BD%9C%E6%88%90%E3%81%A8%E7%95%AA%E5%8F%B7%E4%BB%98%E3%81%91
pattern = re.compile(r'=(=+)(.+?)=', re.MULTILINE)
res = pattern.findall(uk)
for line in res:
print(line[1], len(line[0]))
貪欲マッチの ? とかすぐに出てこなくて焦る
# 024
pattern = re.compile(r'ファイル:(.+?)\|', re.MULTILINE)
res = pattern.findall(uk)
for line in res:
print(line)
# 025
pattern = re.compile(r'''
^\{\{基礎情報.*?$
.*?
^\}\}$
''', re.MULTILINE+re.DOTALL)
data = '\n'.join(pattern.findall(uk))
pattern = re.compile(r'^\|(.+?)\s*=\s*(.+?)$', re.MULTILINE)
res = {}
for t in pattern.findall(data):
res[t[0]] = t[1].replace("\n", '')
memo: re.DOTALL
# 026
def strip_markup(text):
pattern = re.compile(r'(\'{2,5})(.+?)(\1)', re.M)
return pattern.sub(r'\2', text)
pattern = re.compile(r'''
^\{\{基礎情報.*?$
.*?
^\}\}$
''', re.MULTILINE+re.DOTALL)
data = '\n'.join(pattern.findall(uk))
pattern = re.compile(r'^\|(.+?)\s*=\s*(.+?)$', re.MULTILINE)
res = {}
for t in pattern.findall(data):
res[t[0]] = strip_markup(t[1].replace("\n", ''))
print(res)
\1 を知らなかった。またコンパイル済みの pattern.sub() で pattern の /2 が使えるのも当然知らなかった。
# 027
def strip_markup(text):
pattern = re.compile(r'(\'{2,5})(.+?)(\1)', re.M)
text = pattern.sub(r'\2', text)
pattern = re.compile(r'\[\[([^\|]*?)\]\]')
text = pattern.sub(r'\1', text)
pattern = re.compile(r'\[\[(.+?)\|(.+?)\]\]')
return pattern.sub(r'\2', text)
pattern = re.compile(r'''
^\{\{基礎情報.*?$
.*?
^\}\}$
''', re.MULTILINE+re.DOTALL)
data = '\n'.join(pattern.findall(uk))
pattern = re.compile(r'^\|(.+?)\s*=\s*(.+?)$', re.MULTILINE)
res = {}
for t in pattern.findall(data):
res[t[0]] = strip_markup(t[1].replace("\n", ''))
print(res)
# 028
def strip_markup(text):
pattern = re.compile(r'(\'{2,5})(.+?)(\1)', re.M)
text = pattern.sub(r'\2', text)
pattern = re.compile(r'\[\[([^\|]*?)\]\]')
text = pattern.sub(r'\1', text)
pattern = re.compile(r'\[\[(.+?)\|(.+?)\]\]')
text = pattern.sub(r'\2', text)
pattern = re.compile(r'\{\{lang\|[^\|]+?\|([^\|]+)\}\}')
text = pattern.sub(r'\1', text)
# あとの除去は省略
return text
pattern = re.compile(r'''
^\{\{基礎情報.*?$
.*?
^\}\}$
''', re.MULTILINE+re.DOTALL)
data = '\n'.join(pattern.findall(uk))
pattern = re.compile(r'^\|(.+?)\s*=\s*(.+?)$', re.MULTILINE)
res = {}
for t in pattern.findall(data):
res[t[0]] = strip_markup(t[1].replace("\n", ''))
print(res)
# 029
import sys
import pprint
import urllib.parse, urllib.request
pattern = re.compile(r'''
^\{\{基礎情報.*?$
.*?
^\}\}$
''', re.MULTILINE+re.DOTALL)
data = '\n'.join(pattern.findall(uk))
pattern = re.compile(r'^\|(.+?)\s*=\s*(.+?)$', re.MULTILINE)
res = {}
for t in pattern.findall(data):
res[t[0]] = strip_markup(t[1].replace("\n", ''))
file_name = res['国旗画像']
url = 'https://www.mediawiki.org/w/api.php?' \
+ 'action=query' \
+ '&titles=File:' + urllib.parse.quote(file_name) \
+ '&format=json' \
+ '&prop=imageinfo' \
+ '&iiprop=url'
request = urllib.request.Request(url)
connection = urllib.request.urlopen(request)
data = json.loads(connection.read().decode())
print(data['query']['pages'].popitem()[1]['imageinfo'][0]['url'])
あえて標準のライブラリでやったけど、たぶん requests を使ったら圧倒的に楽