言語処理100本ノック 2020 第4章
Created: 2020-05-03
言語処理100本ノック 2020 - NLP100 2020
関連記事: tag 言語処理100本ノック
所感
コードを書く上で難しいということはあまりないが、門外漢のため問題文に用いられる用語が分からず苦戦した。これらのタームを難なく理解できることもこの課題の狙いだと(勝手に)考えることにする。
形態素解析には MeCab を使う。解析結果をファイル(neko.txt.mecab)に保存してから扱うので、mecab-python のようなライブラリをインストールする必要はないから導入は楽だと思う。
code
今回からは IntelliJ IDEA (+ Python プラグイン)を使った。
実際には全問を1ファイルで解いているが、本記事ではコメントや図形を挿入するために分割して記述している部分がある。
#!/usr/local/bin/python3
import pprint
path = '/path/to/neko.txt.mecab'
# 030
with open(path) as f:
s_split = f.read().split('EOS\n')
sentences = []
for s in s_split:
if s == '':
continue
words_list = []
for w in s.split('\n'):
if w == '':
continue
(surface, attr) = w.split('\t')
attrs = attr.split(',')
words_list.append({
'surface': surface,
'base': attrs[6],
'pos': attrs[0],
'pos1': attrs[1]
})
sentences.append(words_list)
pprint.pprint(words_list)
# 031
# リストを均す
from itertools import chain
flattened = list(chain.from_iterable(sentences))
surface_list = []
for d in flattened:
if d['pos'] == '動詞':
surface_list.append(d['surface'])
print(surface_list)
list の flatten は itertool を使うと良いと公式ドキュメントにあった。 reduce を使ったりしてたが、こっちのほうが早いし楽。
# 032 内包表記にした
print([d['base'] for d in flattened if d['pos'] == '動詞'])
# 033
no_list = []
for i in range(len(flattened) - 2):
if flattened[i]['pos'] == '名詞' and flattened[i + 1]['surface'] == 'の' and flattened[i + 2]['pos'] == '名詞':
no_list.append(flattened[i]['surface'] + 'の' + flattened[i + 2]['surface'])
print(no_list)
# 034
connection = ''
connection_list = []
for d in flattened:
if d['pos'] == '名詞':
connection += d['surface']
else:
if connection != '':
connection_list.append(connection)
connection = ''
print(connection_list)
# 035
from collections import Counter
c = Counter([d['surface'] for d in flattened])
most_common_list = c.most_common()
print(most_common_list)
出現回数を数える場合は Counter を使うのが便利で、特に[most_common](https://docs.python.org/ja/3/library/collections.html#collections.Counter.most_common] はタプル (要素, 出現回数) を出現回数順に取得できる。
# 036
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
height = np.array([most_common_list[i][1] for i in range(10)])
left = np.array([most_common_list[i][0] for i in range(10)])
fig = plt.figure()
rcParams["font.family"] = 'Hiragino Maru Gothic Pro'
plt.bar(left, height)
fig.savefig('036.png')
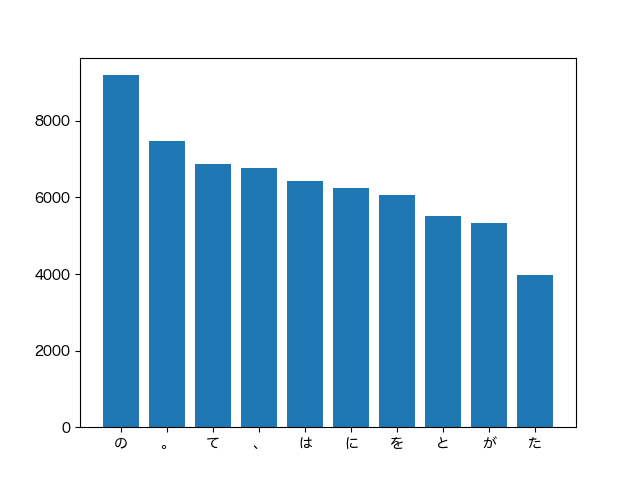
Linux だったら IPAex フォントを入れておくのが良いのだろうか。 Mac なのでプリインストールのフォントを使った。
# 037
cooccurrences = []
for s in sentences:
words = [x['surface'] for x in s]
if '猫' in words:
cooccurrences.extend([x for x in words if x != '猫'])
c = Counter(cooccurrences)
most_common_list_cat = c.most_common()
height = np.array([most_common_list_cat[i][1] for i in range(10)])
left = np.array([most_common_list_cat[i][0] for i in range(10)])
fig = plt.figure()
rcParams["font.family"] = 'Hiragino Maru Gothic Pro'
plt.bar(left, height)
fig.savefig('037.png')
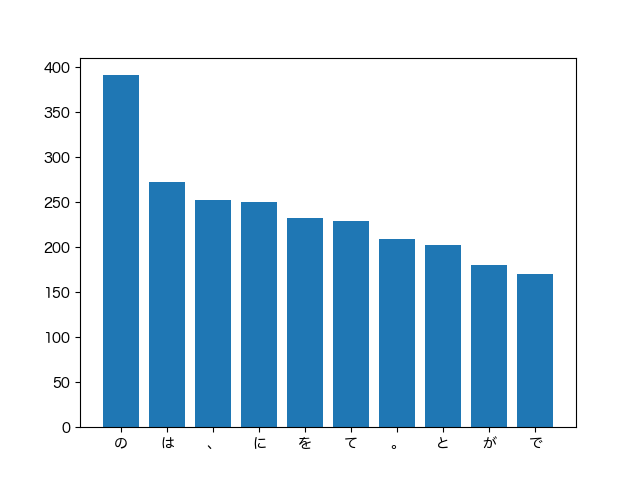
「猫」と同じ文中に現れる回数を計算すればよいだろうか。きれいに書こうとしなければ簡単。
# 038
fig = plt.figure()
plt.hist([x[1] for x in most_common_list], bins=20, range=(1, 100))
fig.savefig('038.png')
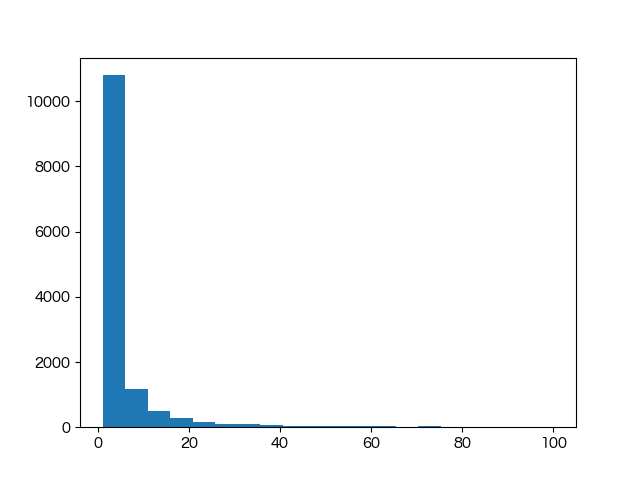
035 の結果を使う。表示する頻度を全体にすると可視化の意味がなくなるので100位程度までに絞る。
# 039
fig = plt.figure()
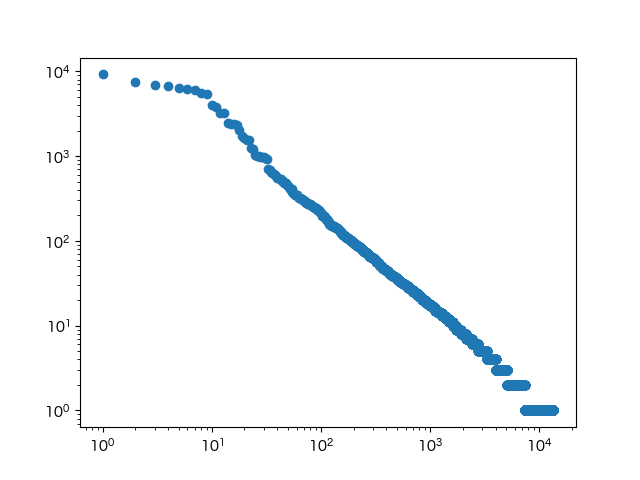
plt.scatter([i+1 for i in range(len(most_common_list))], [x[1] for x in most_common_list])
plt.xscale('log')
plt.yscale('log')
fig.savefig('039.png')