言語処理100本ノック 2020 第5章
Created: 2020-05-11
言語処理100本ノック 2020 - NLP100 2020
関連記事: tag 言語処理100本ノック
所感
いよいよタームの難度が上がってきた。
code
040
#!/usr/local/bin/python3
class Morph:
def __init__(self, word):
self.surface = word['surface']
self.base = word['base']
self.pos = word['pos']
self.pos1 = word['pos1']
src = 'neko.txt.cabocha'
with open(src) as f:
sentence_list = f.read().split('EOS\n')
sentence_list = [x for x in sentence_list if x != '']
morph_list = []
for sentence in sentence_list:
words_list = []
for word in sentence.strip().split('\n'):
if word[0] == '*':
continue
(surface, attr) = word.split('\t')
attr = attr.split(',')
morph = Morph({
'surface': surface,
'base': attr[6],
'pos': attr[0],
'pos1': attr[1]
})
words_list.append(morph)
morph_list.append(words_list)
for m in morph_list[2]:
print(vars(m))
041
以下、前の課題で使ったコードは省略する
# 041
for chunk in sentence_chunks[7]:
print(vars(chunk))
for morph in chunk.morphs:
print(vars(morph))
042
# 042
for sentence in sentence_chunks:
for chunk in sentence:
if int(chunk.dst) != -1:
print(
''.join([m.surface for m in chunk.morphs if m.pos != '記号']) + '\t' +
''.join([m.surface for m in sentence[int(chunk.dst)].morphs if m.pos != '記号'])
)
043
for sentence in sentence_chunks:
for chunk in sentence:
if int(chunk.dst) != -1:
if '名詞' in [m.pos for m in chunk.morphs] and '動詞' in [m.pos for m in sentence[int(chunk.dst)].morphs]:
print(
''.join([m.surface for m in chunk.morphs if m.pos != '記号']) + '\t' +
''.join([m.surface for m in sentence[int(chunk.dst)].morphs if m.pos != '記号'])
)
044
rel = []
# 041 に準じて8文目だけを対象にする
sentence = sentence_chunks[7]
for chunk in sentence:
if int(chunk.dst) != -1:
modifier = ''.join([m.surface for m in chunk.morphs if m.pos != '記号'])
modifiee = ''.join([m.surface for m in sentence[int(chunk.dst)].morphs if m.pos != '記号'])
rel.append([modifier, modifiee])
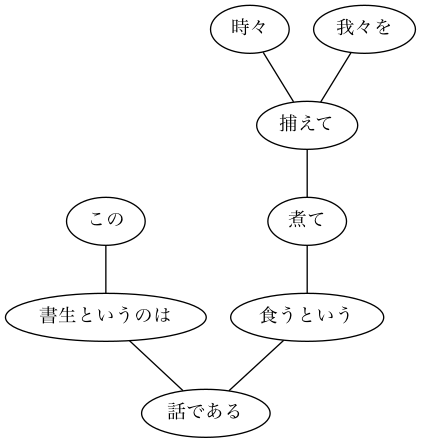
g = pydot.graph_from_edges(rel)
g.write_png('044.png', prog='dot')
045
for sentence in sentence_chunks:
rel = {}
for key, chunk in enumerate(sentence):
morphs = [m for m in chunk.morphs if m.pos == '動詞']
if len(morphs) > 0:
predicate = morphs[0].base
cases = []
for src in chunk.srcs:
cases.extend([m.surface for m in sentence[src].morphs if m.pos == '助詞'])
case = ' '.join(cases)
if case != '':
print(predicate + '\t' + case)
$ python3 45.py > 45.txt
# コーパス中で頻出する述語と格パターンの組み合わせ
$ cat 45.txt | sort | uniq -c | sort -nr | head -n 50
# 「する」「見る」「与える」という動詞の格パターン
$ cat 45.txt | grep '見る' | sort | uniq -c | sort -nr | head -n 50
046
for sentence in sentence_chunks:
rel = {}
for key, chunk in enumerate(sentence):
morphs = [m for m in chunk.morphs if m.pos == '動詞']
if len(morphs) > 0:
predicate = morphs[0].base
cases = []
arguments = []
for src in chunk.srcs:
if src != key:
cases.extend([m.surface for m in sentence[src].morphs if m.pos == '助詞'])
arguments.append(''.join([m.surface for m in sentence[src].morphs]))
case = ' '.join(cases)
argument = ' '.join(arguments)
if case != '':
print(predicate + '\t' + case + '\t' + argument)
047
for sentence in sentence_chunks:
rel = {}
for key, chunk in enumerate(sentence):
if ('サ変接続' in [m.pos1 for m in chunk.morphs]
and 'を' in [m.surface for m in chunk.morphs]
and key < len(sentence) - 1
and sentence[key + 1].morphs[0].pos == '動詞'
):
# 述語
predicate = ''.join([m.surface for m in chunk.morphs]) + sentence[key + 1].morphs[0].base
if len(chunk.srcs) > 0:
modifiers = [sentence[int(src)].morphs for src in chunk.srcs]
modifiers_ = [list(filter(lambda x: '助詞' in x.pos, morphs)) for morphs in modifiers]
modifiers_surfaces = [[morph.surface for morph in morphs] for morphs in modifiers_]
modifiers_surfaces = list(filter(lambda x: x != [], modifiers_surfaces))
modifiers_surfaces = [morphs[0] for morphs in modifiers_surfaces]
# print(modifiers_surfaces)
modifiers_texts = list(filter(lambda x: '助詞' in [m.pos for m in x], modifiers))
modifiers_texts = [''.join([m.surface for m in mt]) for mt in modifiers_texts]
if len(modifiers_texts) > 0:
print('\t'.join([predicate, ' '.join(modifiers_surfaces), ' '.join(modifiers_texts)]))
$ python3 47.py > 47.txt
$ cut -f 1 47.txt | sort | uniq -c | sort -nr | head
$ cut -f 1,2 47.txt | sort | uniq -c | sort -nr | head
048
for sentence in sentence_chunks:
for chunk in sentence:
texts = []
if len([morph for morph in chunk.morphs if morph.pos == '名詞']) > 0 and chunk.dst != -1:
current_chunk = chunk
texts.append(''.join([morph.surface for morph in current_chunk.morphs]))
next_chunk = sentence[int(current_chunk.dst)]
while int(current_chunk.dst) != -1:
texts.append(''.join([morph.surface for morph in next_chunk.morphs]))
current_chunk = next_chunk
next_chunk = sentence[next_chunk.dst]
print(' -> '.join(texts))
049
def convert(sentence):
pl, nl = [], [chunk for chunk in sentence if '名詞' in [m.pos for m in chunk.morphs]]
for i in range(len(nl) - 1):
st1 = [''.join([m.surface if m.pos != '名詞' else 'X' for m in nl[i].morphs])]
for e in nl[i + 1:]:
dst, p = nl[i].dst, []
st2 = [''.join([m.surface if m.pos != '名詞' else 'Y' for m in e.morphs])]
while int(dst) != -1 and dst != sentence.index(e):
p.append(sentence[int(dst)])
dst = sentence[int(dst)].dst
if len(p) < 1 or p[-1].dst != -1:
mid = [''.join([m.surface for m in c.morphs if m.pos != '記号']) for c in p]
pl.append(st1 + mid + ['Y'])
else:
mid, dst = [], e.dst
while not sentence[int(dst)] in p:
mid.append(''.join([m.surface for m in sentence[int(dst)].morphs if m.pos != '記号']))
dst = sentence[int(dst)].dst
ed = [''.join([m.surface for m in sentence[int(dst)].morphs if m.pos != '記号'])]
pl.append([st1, st2 + mid, ed])
return pl
for sentence in sentence_chunks:
pl = convert(sentence)
for p in pl:
if isinstance(p[0], str):
print(' -> '.join(p))
else:
print(p[0][0], ' -> '.join(p[1]), p[2][0], sep=' | ')
49 についてはタームが理解できなかったのでほぼ写経。コードから意図を汲み取ることが必要。