MySQL で ngram/mecab 全文パーサーを使うメモ
Created: 2022-04-19
この記事では https://github.com/tbsmcd/mysql_ngram_mecab_sample を用いる。
この保育園の名前、スペースを入れないと検索できないんだけど
たとえば MySQL に保育園テーブルを持っているとする。 「福岡 博多保育園」という保育園があり、
SELECT *
FROM nursery
WHERE name LIKE '%福岡博多%';
のようなクエリで検索してもヒットしない。こういう場合には形態素解析や N-gram を元にインデックスを作成する全文検索の手法を用いたい。
形態素解析によるインデックス
解析用の辞書を使い、文章を単語単位に区切って索引化する。
'吾輩', 'は', '猫', 'で', 'ある', '。'
形態素解析の例文には古来より「吾輩は猫である」冒頭を使う伝統がある。
一般に形態素解析を用いた索引は
- インデックス作成速度は遅い
- 検索ノイズは少ない
- 辞書が必要
のような特徴があり、 MySQL mecab 全文パーサーを用いる場合には mecab をインストールする必要があるため、例えば Amazon RDS for MySQL のようなサービスでは使えない。
N-gram によるインデックス
N 文字ずつに分けて索引化する。 n=2 の場合
'吾輩', '輩は', 'は猫', '猫で', 'であ', 'ある', 'る。'
というように。
一般に N-gram を用いた索引は
- インデックス作成速度は速い
- 検索ノイズが多い
- 辞書が不要
のような特徴があり、 MySQL ngram 全文パーサーを用いるには MySQL5.7 以上であれば特別なものは要らない。
使い方
設定
基本的には公式のドキュメントに全部書いてあるので、 ngram の場合は my.cnf などにトークンサイズを書けばよく、mecab の場合はそれに加えて mecab で使用する辞書のパスなどを記す必要がある。
https://dev.mysql.com/doc/refman/8.0/ja/fulltext-search-ngram.html
https://dev.mysql.com/doc/refman/8.0/ja/fulltext-search-mecab.html
インデックスを作成
今回使ったものでは INSERT したあとに
ALTER TABLE nursery_ngram ADD FULLTEXT INDEX kana_name (name_kana,name) WITH PARSER ngram;
などをしてインデックスを作成しているが、 CREATE TABLE 時に作成しても良い。
例: https://dev.mysql.com/doc/refman/8.0/ja/fulltext-search-ngram.html より
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body) WITH PARSER ngram
) ENGINE=InnoDB CHARACTER SET utf8mb4;
検索クエリ
検索ワードと一致する度合いが高い順に表示したい場合
SELECT *, MATCH(name) AGAINST('第2保育園' IN NATURAL LANGUAGE MODE) as score
FROM nursery_mecab
ORDER BY score DESC;
のように使う。 score の値の加減を設定するとか、 LIMIT を設定するなどをしても良さそう。
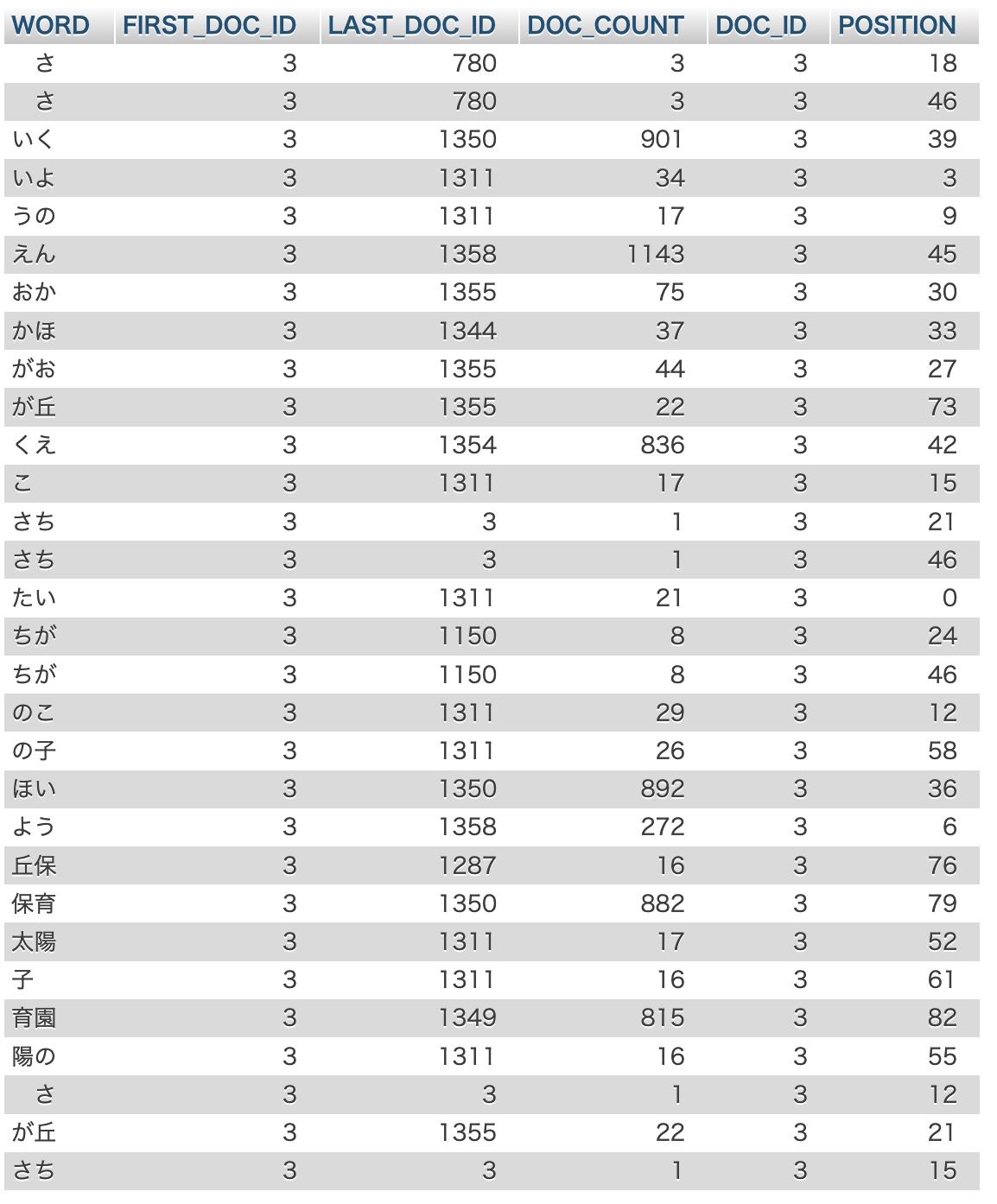
インデックスの見方
SET GLOBAL innodb_ft_aux_table="sample/nursery_ngram";
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_TABLE ORDER BY doc_id LIMIT 30;
使えるのか?
検索精度を上げたい場合には mecab パーサが欲しいが、 RDS 等を使っている場合には使用できない。しかし冒頭に書いたスペースの有無や部分的な表記の不一致は ngram パーサでも拾える。要は使いみち次第。せっかく調べたので覚えておきたい。